- fastp是一个非常方便的基因组数据处理软件,之前在质控的环节就有用到它。
- 这个软件比较方便的地方就是对于处理前后的数据情况会输出一个可视化的网页报告,可以直接查看,报告内容也十分的简单易懂。
- 对于单个数据或者少数数据直接这么查看是比较方便的,但是对于大批量的数据进行处理以后,要还是一个一个报告查看,就让人很抓狂了。
- 最近就碰到了这么一个问题,于是写了一个python小脚本,进行批量结果的可视化,做一下笔记,怕以后忘了。
- 要进行批量可视化的前提是可视化的数据,fastp在处理完数据后,除了一个网页格式报告之外,还有一个json格式的报告,这就是我们的数据来源。
- 本脚本使用python3.x的版本,设计第三方库如下:
- pandas
- matplotlib
首先为这个脚本新建一个目录,并在目录下新建一个report目录(目录名随意)和一个python脚本(脚本名随意),report目录用来放fastp的json格式报告,如图,我的目录下面就放了两百多份报告。

- 这个实现本身很简单,主要要考虑的一点是WGS数据很多时候不是一个sample一对fastq文件,很多时候一个sample对应好多对fastq文件,那么fastp也会输出多个报告,对于这些报告我们要进行合并。
- 下面就来解析一下脚本
先上完整脚本
1 | import json, os |
首先导入相应的库,其中json和os是内置库,分别用来解析json文件以及查看文件。json格式的解析很简单,其实json可以看成是python里面的字典,下面是简单的json库使用:
1
2
3
4
5
6
7
8import json
# 输出 json 数据
with open('data.json', 'w') as f:
json.dump(data, f)
# 读取数据
with open('data.json', 'r') as f:
data = json.load(f)
一般情况下,在当前目录运行的脚本,直接用相对路径就行,但是也有可能你的报告不在当前目录下,那么第5行和第10行的
'./report'就要改成你报告所在目录的位置,同时report这个目录名也要改成你自己存放json格式的目录名。如何合并一个sample的报告结果
1
2
3for k,v in result_dict.items():
key = k.split('_')[0]
...这一步的工作就是合并结果,在我的结果里,虽然一个sample有时候会被分为好多个数据,但是数据的前缀的一部分都是一样的,且以
_分割。这个脚本提取了raw data中
total_bases和q30_bases的数据,这是因为这一块是需要和测序公司核对的部分,一般公司需要交付 90G 的raw data,且Q30要80%以上。其实fastp结果里还有很多其他可以提取的数据,完全可以根据需要提取作图,还是很简单的。最后一个图是看一下,如果去掉duplicate的数据,那么raw data还有多少数据量。
展示一个结果图。
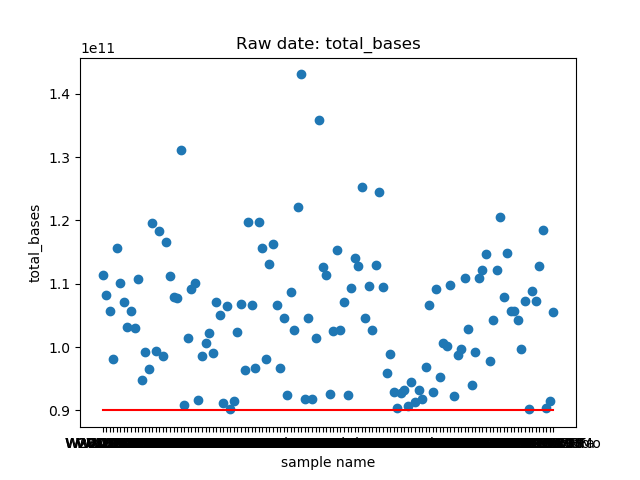
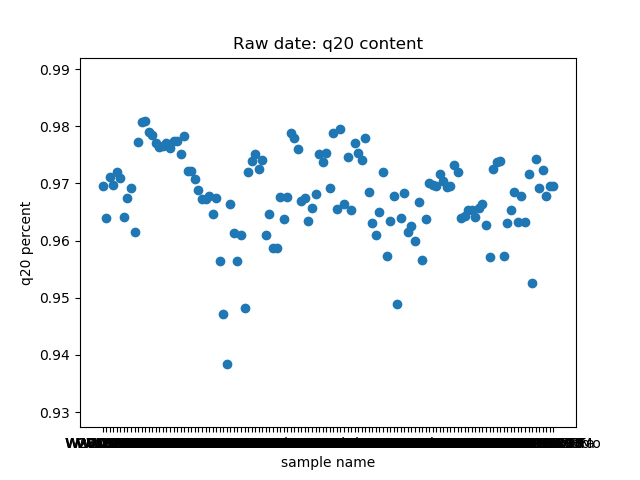
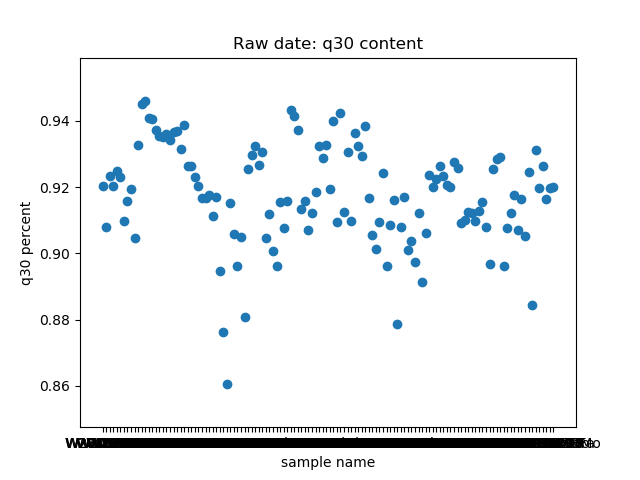
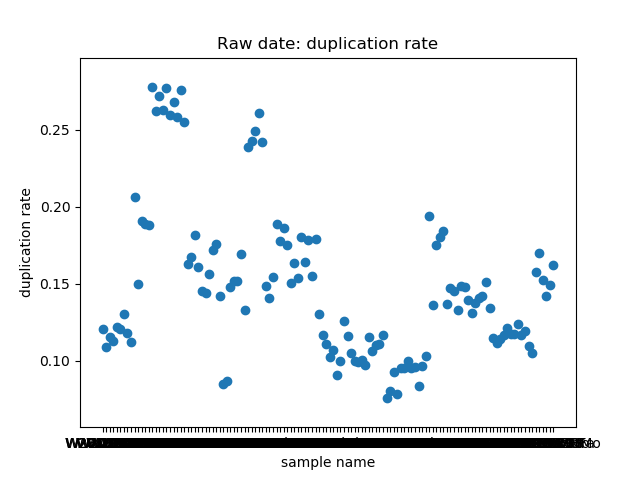
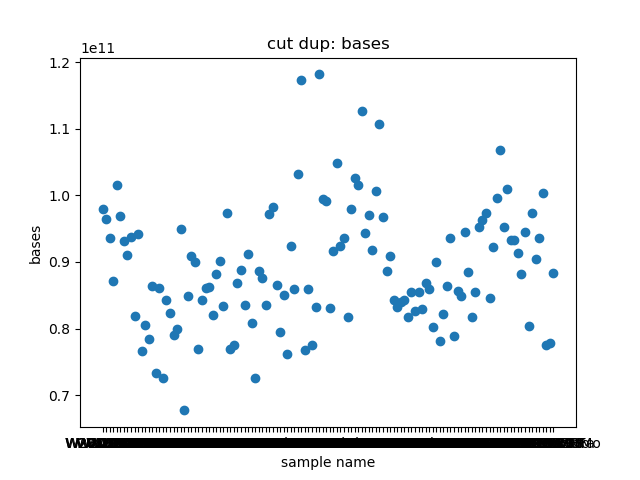
脚本本身超级简单,我看半天实在也不知道还有哪里需要解释的,如果有什么错误或者写的不好的还请见谅了。
水平有限,要是存在什么错误请指出,可发送邮箱至shiyuant@outlook.com!请大家多多批评指正,相互交流,共同成长,谢谢!!!